
简简单单来个DeepSeek-V3.2-Exp 大解剖~附case评测
简简单单来个DeepSeek-V3.2-Exp 大解剖~附case评测家人们,就在国庆放假前的今天凌晨,那个总在节前“搞事”的 DeepSeek,又双叒叕深夜悄然上线了!讲真,DeepSeek 是真的不考虑我们媒体人的死活啊哈哈!每次都卡着放假前更新,之前大家都转发的吐槽截图,本人又翻出来了:
来自主题: AI技术研报
10493 点击 2025-10-03 00:01
 搜索
搜索
家人们,就在国庆放假前的今天凌晨,那个总在节前“搞事”的 DeepSeek,又双叒叕深夜悄然上线了!讲真,DeepSeek 是真的不考虑我们媒体人的死活啊哈哈!每次都卡着放假前更新,之前大家都转发的吐槽截图,本人又翻出来了:

在今年 3 月 DeepSeek 和豆包占领国内产品月活用户增速前两名的时候,以第三姿态紧随其后的,是红果短剧。两者之间这个巧合的「偶遇」,意外也不意外。反映的正是我们当下经历的最重要的技术与文化浪潮。

DeepSeek v3.2有一个新改动,在论文里完全没提,只在官方公告中出现一次,却引起墙裂关注。开源TileLang版本算子,其受关注程度甚至超过新稀疏注意力机制DSA,从画线转发的数量就可以看出来。
刚发V3.1“最终版”,DeepSeek最新模型又来了!DeepSeek-V3.2-Exp刚刚官宣上线,不仅引入了新的注意力机制——DeepSeek Sparse Attention。还开源了更高效的TileLang版本GPU算子!
就在最近,由耶鲁大学唐相儒、王昱婕,上海交通大学徐望瀚,UCLA万冠呈,牛津大学尹榛菲,Eigen AI金帝、王瀚锐等团队联合开发的Eigen-1多智能体系统实现了历史性突破
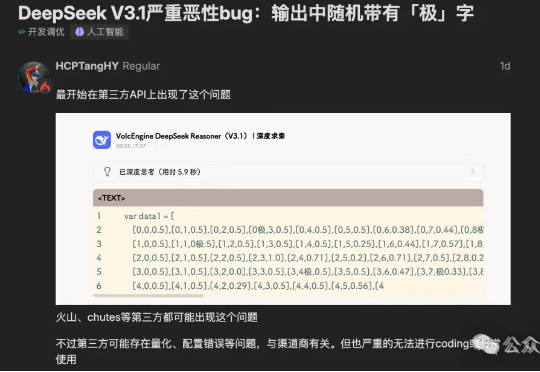
“极你太美”bug,果然在DeepSeek V3.1最新版本中被修复了。DeepSeek-V3.1刚刚更新至DeepSeek-V3.1-Terminus版本。
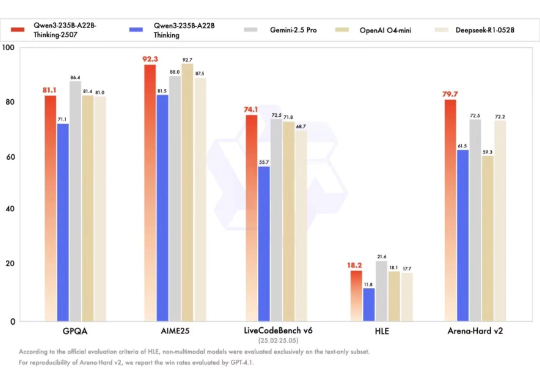
2025 年 9 月 19 日,亚马逊云科技官宣:Qwen3 和 DeepSeek v3.1,首次上线 Amazon Bedrock ,正式对外提供服务,再一次引起了全球生成式 AI 市场对 Amazon Bedrock 这一产品的关注。
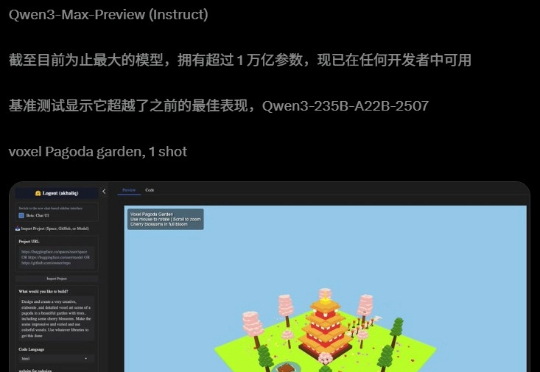
阿里迄今为止,参数最大的模型诞生了!昨夜,Qwen3-Max-Preview(Instruct)官宣上线,超1万亿参数性能爆表。在全球主流权威基准测试中,Qwen3-Max-Preview狂揽非推理模型「C」位,直接碾压Claude-Opus 4(Non-Thinking)、Kimi-K2、DeepSeek-V3.1。
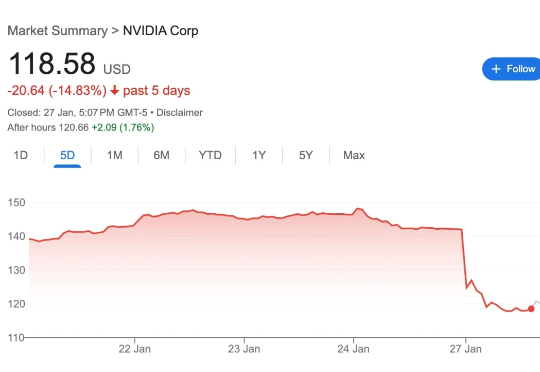
随着DeepSeek R1、Kimi K2和DeepSeek V3.1混合专家(MoE)模型的相继发布,它们已成为智能前沿领域大语言模型(LLM)的领先架构。由于其庞大的规模(1万亿参数及以上)和稀疏计算模式(每个token仅激活部分参数而非整个模型),MoE式LLM对推理工作负载提出了重大挑战,显著改变了底层的推理经济学。
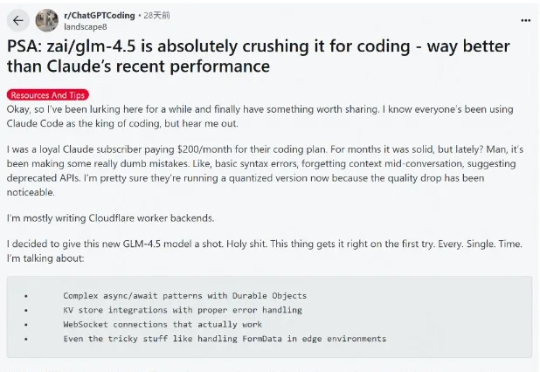
这段时间 AI 编程的热度完全没退,一个原因是国内接连推出开源了不少针对编程优化的大模型,主打长上下文、Agent 智能体、工具调用,几乎成了标配,成了 Claude Code 的国产替代,比如 GLM-4.5、DeepSeek V3.1、Kimi K2。